
✨ About me
Hi, everyone! I am currently a second-year PhD student (10.2024-) at King’s College London, NLP group, School of Informatics. I am fortunate to be supervised by Dr. Lin Gui and Prof. Yulan He. I finished my MSC AI at the University of Edinburgh and my BEng EEE project jointly at the University of Edinburgh and North China Electric Power University(NCEPU). I am fortunate to be supervised by Prof. Frank Keller for my MSC and Dr. Jiabin Jia for my BEng.
In addition to research, I interned for four months as a full-stack engineer specialising in voice cloning algorithms at 01.AI.
🔍 Research Summary
My research interests lie in the intersection of Natural Language Processing and multi-modal understanding, with a focus on aligning retrieval, reasoning, and model internal representations for reliable and efficient language models. Generally speaking, my goal is 1) Advancing retrieval-augmented and embedding-based frameworks to robustly connect retrieved evidence with LLMs, improving answer faithfulness and controllability in long-context generation. 2) Developing the robust cross-modality alignment and comprehension abilities in real-world, interactive communication environments. My long-term vision is to build principled AI systems that unify retrieval, reasoning, and multi-modal understanding into trustworthy, efficient, and human-aligned communicative agents. Specifically, my latest research focuses on:
-
Retrieval-Augmented Generation (RAG) in Text Generation/QA, such as EEE-QA, COLING 2024: A gate layer framework in multi-choice question answering, EmbQA, ACL 2025 Main: A rerank-reading system with an unsupervised contrastive learning framework in the rerank and an exploratory embedding mechanism in the reading framework, and Spectrum Projection Score (SPS), AAAI 2026 Oral: propose a supervision-free metric SPS quantifying semantic alignment between retrievals and reader models and a test-time framework that improves RAG performance via SPS-guided sampling and filtering.
-
Reasoning in latent space, such as CODI, 2025 EMNLP Main: Train a large language model (LLM) to perform reasoning without explicitly generating Chain-of-Thought (CoT) tokens.
-
Multi-modal interpretability and application, such as Causal and temporal inference in videos QA, ACL ALVR 2024, and Human motion video generation, TPAMI 2025
🔥 News
- 2025.11: Our paper Spectrum Projection Score: Aligning Retrieved Summaries with Reader Models in Retrieval-Augmented Generation has been accepted by AAAI 2026 Oral🌟! 🎉
- 2025.08: Our paper CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation has been accepted by EMNLP 2025 Main! 🎉
- 2025.07: Our paper Human motion video generation: A survey has been accepted by TPAMI 2025! 🎉
- 2025.05: Our paper Beyond Prompting: An Efficient Embedding Framework for Open-Domain Question Answering has been accepted by ACL 2025 Main! 🎉
- 2024.10: I start my PhD📚 journey at King's College London, NLP group!
- 2024.06: Our paper Causal and Temporal Inference in Visual Question Generation by Utilizing Pre-trained Models has been accepted by ACL ALVR 2024! 🎉
- 2024.02: Our paper Exploring Effective and Efficient Question-Answer Representations has been accepted by COLING 2024! 🎉
- 2023.12: Our paper EEE-QA: Exploring Effective and Efficient Question-Answer Representations has been accepted by AAAI 2024 DEPLOYABLE AI! 🎉
🚀 I am always open to new collaborations and engaging discussions. Feel free to reach out if you are interested in working together or just want to chat!
📚 Text Generation & Retrieval/RAG
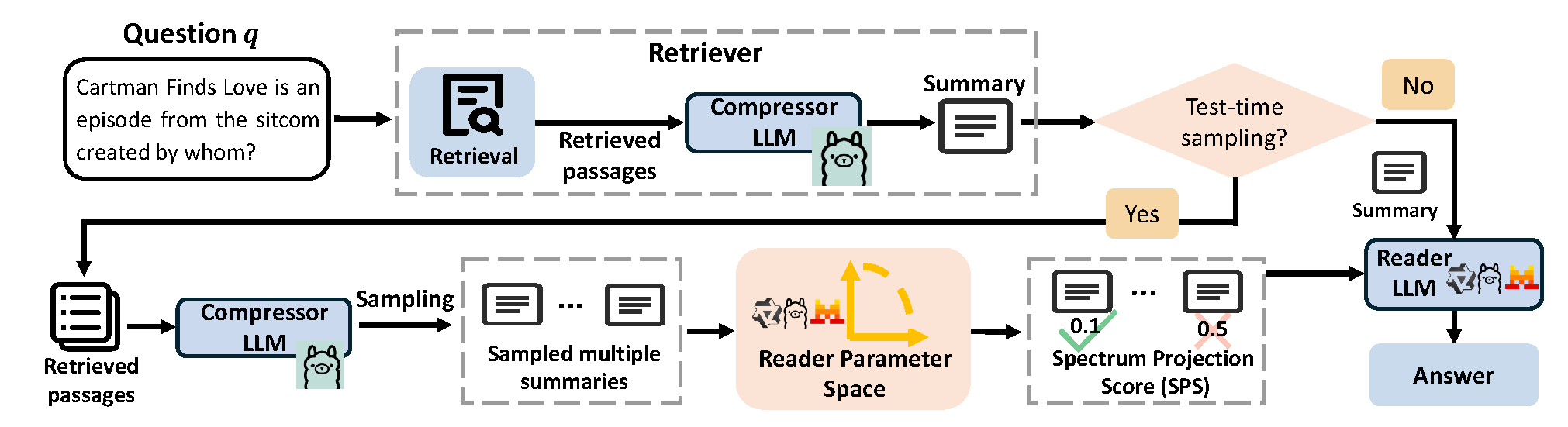
Beyond Perplexity: Let the Reader Select Retrieval Summaries via Spectrum Projection Score
Zhanghao Hu, Qinglin Zhu, Siya Qi, Yulan He, Hanqi Yan, Lin Gui
[Project] [Code]
- Proposes SPS, a supervision-free metric to assess semantic alignment between retrieved summaries and LLM representations.
- Introduces xCompress, an inference-time controller that ranks and compresses retrievals to improve generation and clarify retrieval–generation interaction.
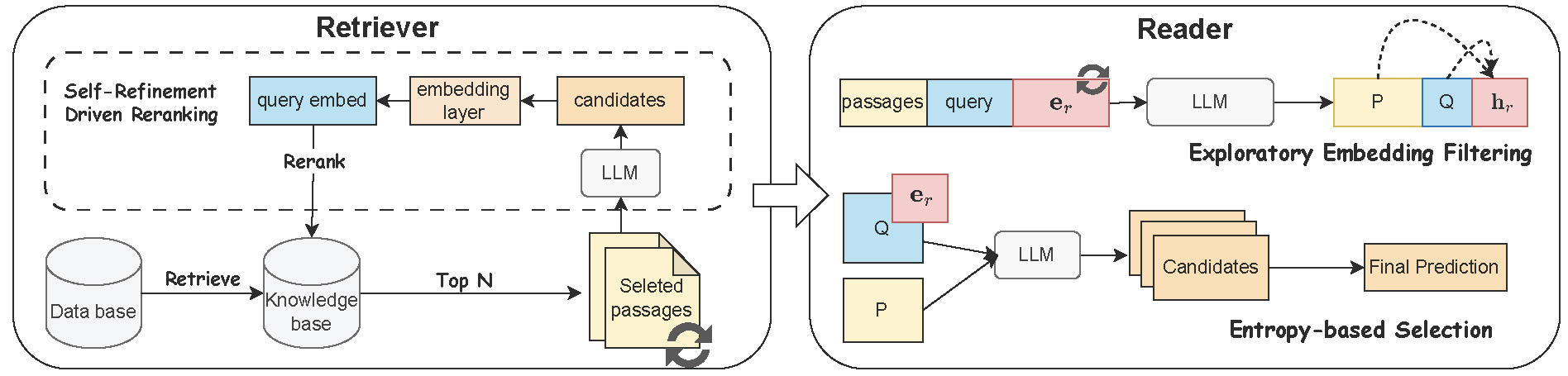
Beyond Prompting: An Efficient Embedding Framework for Open-Domain Question Answering
Zhanghao Hu, Hanqi Yan, Qinglin Zhu, Zhenyi Shen, Yulan He, Lin Gui
[Project] [Code]
- Reordering retrieved passages to highlight those most likely to contain correct answers by refining query representations via lightweight linear layers under an unsupervised contrastive learning objective.
- Introduce an exploratory embedding that broadens the model’s latent semantic space to diversify candidate generation and employs an entropy-based selection mechanism to choose the most confident answer automatically
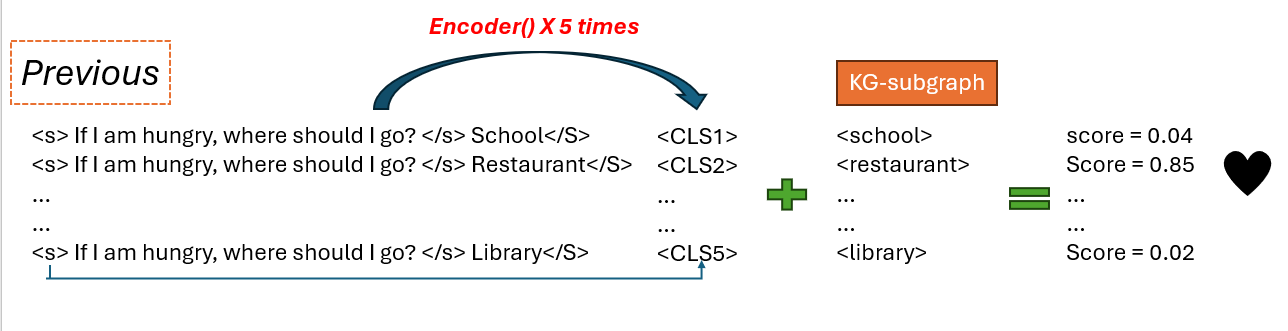
EEE-QA: Exploring Effective and Efficient Question-Answer Representations
Zhanghao Hu, Yijun Yang, Junjie Xu*, Yifu Qiu, Pinzhen Chen
[Project]
- This work challenges the existing question-answer encoding convention and explores finer representations. We experiment with different PLMs, and with and without the integration of knowledge graphs. Results prove that the memory efficacy of the proposed techniques is with little sacrifice in performance.
🤔 Latent & Efficient Reasoning
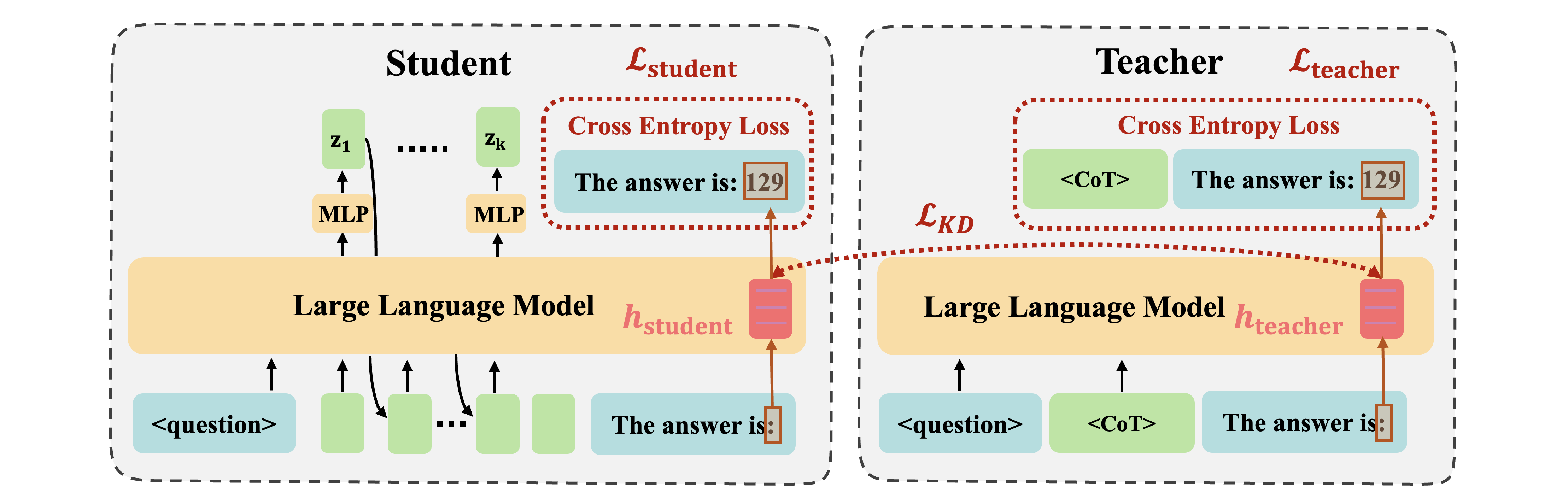
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, Yulan He
[Project]
- CODI (Continuous Chain-of-Thought via Self-Distillation) is a novel framework that distils CoT into a continuous space, where a shared model acts as both teacher and student, jointly learning explicit and implicit CoT while aligning their hidden activation on the token generating the final answer.
 Multi-modal interpretability & application
Multi-modal interpretability & application
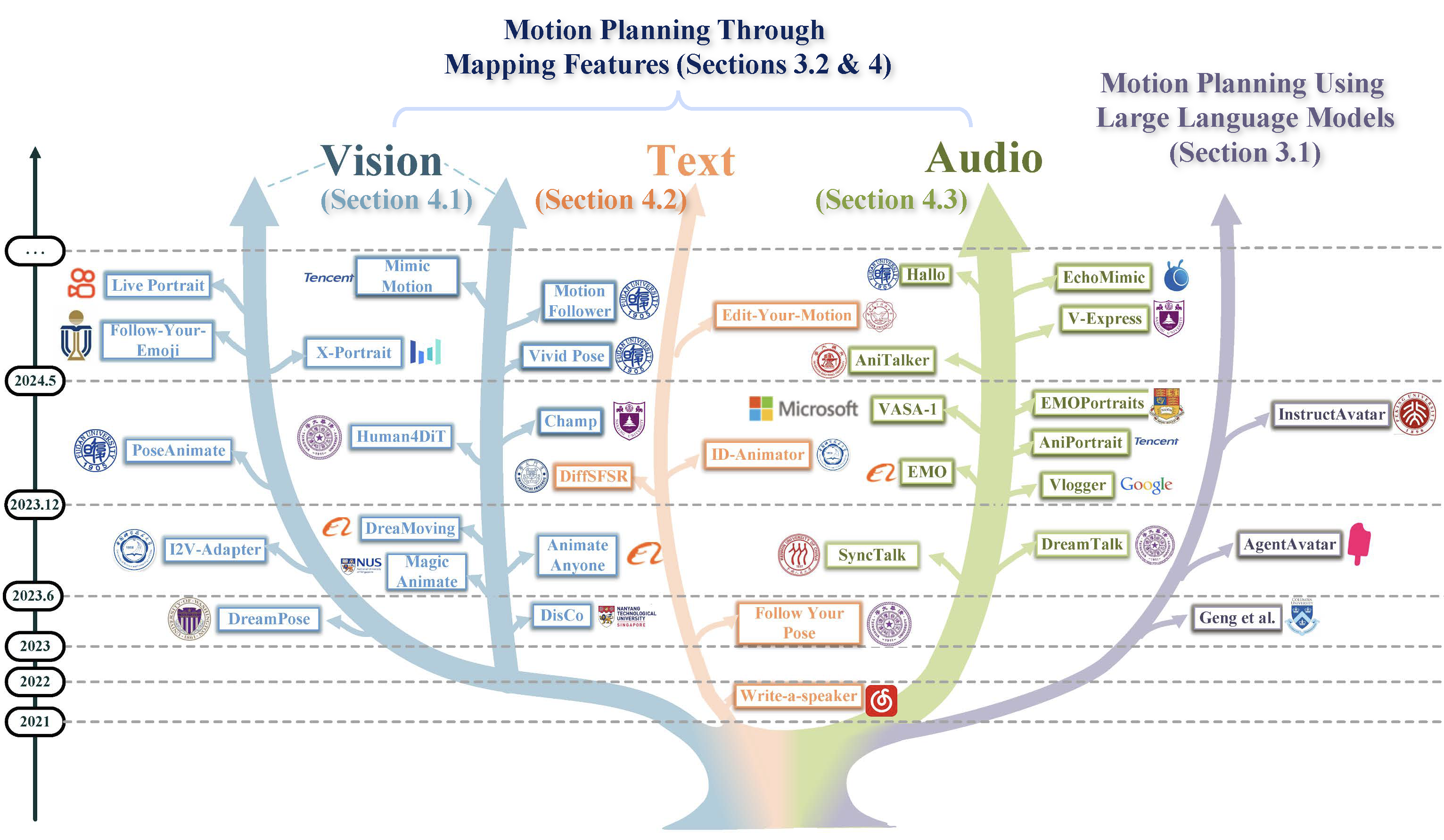
Human motion video generation: A survey
Haiwei Xue, Xiangyang Luo, Zhanghao Hu, Xin Zhang, Xunzhi Xiang, Yuqin Dai, Jianzhuang Liu, Zhensong Zhang, Minglei Li, Jian Yang, Fei Ma, Zhiyong Wu, Changpeng Yang, Zonghong Dai, Fei Richard Yu
[Project]
- This paper addresses this gap by providing an in-depth survey of human motion video generation, encompassing over ten sub-tasks, and detailing the five key phases of the generation process: input, motion planning, motion video generation, refinement, and output.
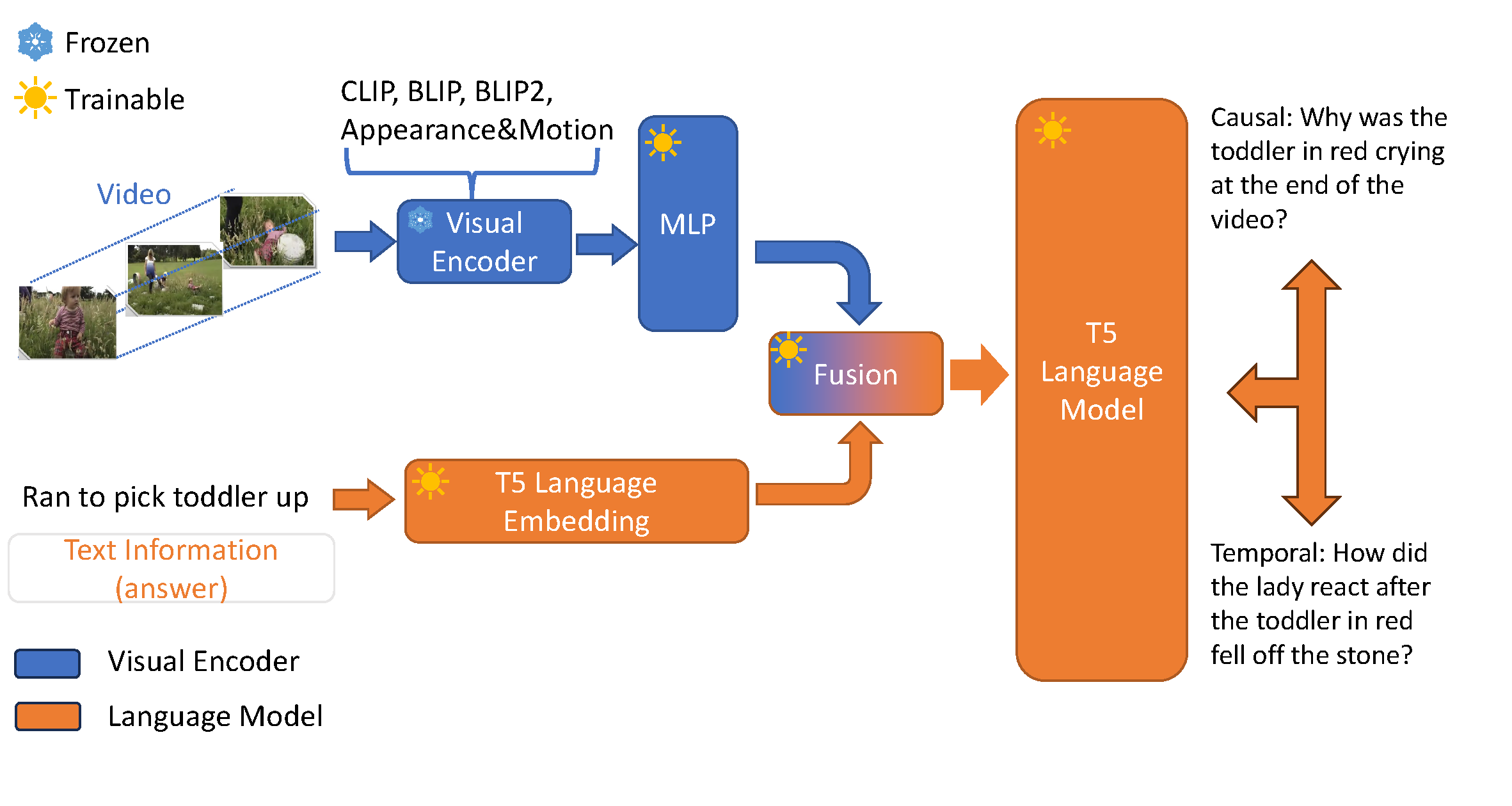
Causal and Temporal Inference in Visual Question Generation by Utilizing Pre-trained Models
Zhanghao Hu, Frank Keller
[Project]
- Our study introduces a framework that leverages vision-text matching pre-trained models to guide language models in recognizing event-entity relationships within videos and generating inferential questions.
🎖 Honors and Awards
-
2023.01 IBM Shortlist for Best Project in Machine Learning Practical Course, Ranked 5/103.
-
2022.06 Outstanding Graduate Award, NCEPU
-
2022.05 £3000 Scholarship, University of Edinburgh, For Excellent 2+2 International Students
-
2021.05 £2500 Scholarship, University of Edinburgh, For Excellent 2+2 International Students
-
2020.10 Third Prize Academic Scholarship, NCEPU, Awarded to top 10% of students
-
2019.10 Second Prize Academic Scholarship, NCEPU, Awarded to top 5% of students
📖 Educations
-
2022.09 – 2023.11, MSc in Artificial Intelligence, University of Edinburgh, Distinction Degree, ranked top ~10%
-
2020.09 – 2022.05, Bachelor in Electronics and Electrical Engineering, University of Edinburgh, First-Class Honour Degree, ranked top ~10%
-
2018.09 – 2020.06, Bachelor in Electrical Engineering and Its Automation, North China Electric Power University (NCEPU) Ranked ~15%
💬 Invited Talks
💻 Internships
- 2024.04 - 2024.08, Research Intern at 01.AI.